SQL이 느린 이유
결론은 I/O 때문입니다.
프로그램, 즉 여러 프로세스가 CPU를 공유하고, 주어진 시간에 하나의 프로세스만 CPU를 사용하므로 준비 시간이 필요합니다. ⇒ I/O 호출 수가 증가할수록 디스크 경합이 증가하고 대기 시간이 증가하며 필연적으로 성능 저하가 발생합니다.
데이터 저장 구조
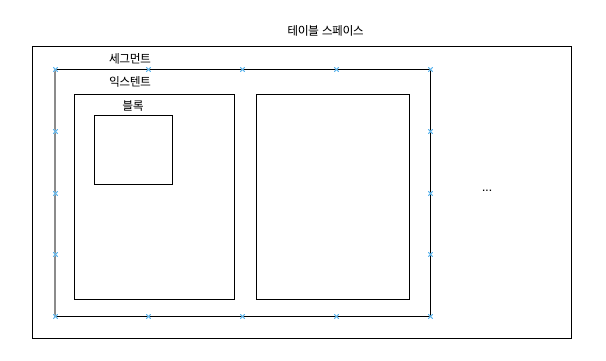
")


테이블스페이스 – 세그먼트 – 익스텐트 – 블록 – 행이 있습니다.
분절
세그먼트는 데이터 저장을 위한 공간이 필요한 객체입니다. B. 테이블과 인덱스.
정도
공간을 확장하는 유닛
블록(mysql의 페이지)
사용자가 입력한 기록을 실제로 저장하는 공간
// oracle
select segment_type, tablespace_name, extent_id, file_id, block_id, blocks
from dba_extents
where owner = USER
and segment_name="MY_SEGMENT"
order by extent_id;
// mysql
SELECT table_name, data_length, index_length
FROM information_schema.tables
WHERE table_schema="LiveCommerceJpa"
AND table_name="broadcast";
블록 장치 I/O
DBMS가 데이터를 읽고 쓰는 단위는 블록입니다. ⇒ 인덱스와 테이블도 블록 단위로 데이터를 읽고 씁니다.
레코드를 읽으려고 해도 전체 블록을 읽습니다.
순차적 액세스
논리적 또는 물리적으로 연결된 순서에 따라 블록을 순차적으로 읽는 방식(정방향 및 역방향 포인팅 주소 값으로 읽음).
Oracle은 세그먼트 헤더에 맵으로 익스텐트를 가지고 있습니다. 즉, 세그먼트 맵에서 각 영역을 순차적으로 읽는다. ⇒ 전체 테이블 스캔입니다.
임의 접근
순서를 따르지 않고 레코드를 읽을 수 있는 액세스 차단
논리적 I/O – 물리적 I/O
DB 버퍼 캐시
DB 버퍼 캐시는 데이터 캐시이며 디스크에서 읽은 데이터 블록을 저장합니다. db 버퍼 캐시가 없으면 자주 읽는 블록을 매번 디스크에서 읽어오기 때문에 매우 비효율적입니다. 그래서 SQL이 실행될 때 DB Buffer Cache를 먼저 읽어서 존재하면 사용하고 없으면 디스크에서 읽어서 Cache한다.
Logical I/O(Memory I/O) – SQL 처리 중 발생하는 총 블록 I/O(여러 번 실행해도 매번 읽는 횟수는 같음)
물리적 I/O – 디스크의 총 블록 I/O(디스크에서 읽은 블록 I/O는 버퍼 캐시에서 찾을 수 없음)
버퍼 캐시 적중률
BCHR = (캐시에서 찾은 블록 수 / 읽은 총 블록 수) * 100
= (논리적 - 물리적 / 논리적 ) * 100
= (1 - 물리적 / 논리적 ) * 100
결론은 논리적 I/O를 줄여 SQL 성능을 향상시키는 것입니다.
논리적 IO를 줄이는 방법은 무엇입니까?
총 블록 수를 줄입니다.
mysql이 수집하는 통화 통계 정보는 무엇인가요?
단일 블록 I/O, 다중 블록 I/O
단일 블록 I/O
- 한 번에 하나의 블록을 요청하고 메모리에 로드
- 인덱스와 테이블이 사용됨
다중 블록 I/O
- 캐시에 없는 특정 블록을 읽으려면 I/O 호출을 하고 디스크의 블록과 인접 블록(여러 블록)을 요청하여 메모리에 로드합니다.
- 전체 테이블 스캔이 사용됨(다중 블록 I/O 장치가 클수록 좋음)
전체 테이블 스캔 대 인덱스 범위 스캔
테이블을 완전히 스캔
- 전체 블록 읽기
- 순차적 액세스
- 다중 블록 I/O
- 메모리 스캔 성능이 좋아지면 좋아질 것입니다.
⇒ I/O를 통해 한번에 가져옴. 적은 양의 데이터를 찾을 때는 비효율적입니다.
인덱스 범위 스캔
- 인덱스에서 지정된 양을 스캔하고 읽습니다.
- 임의 접근
- 단일 블록 I/O
⇒ 레코드를 읽을 때마다 I/O를 통해 가져오므로 대량의 데이터를 검색할 때 비효율적임
인덱스가 성능을 저하시키는 경우가 있습니다. 예를 들어 배치 프로그램이 있습니다.